
Fast, outside-in API Testing w/ Postgres
Using virtual databases to test end-to-end at lightning speed

Over the past 7 years there’s one pattern I keep coming back to for every new API project, I’m not sure it has a name but it might be best described as “virtual database per endpoint” pattern. It’s an incredibly effective pattern for doing “outside-in testing” (AKA London-style TDD), where you try to avoid unit tests and prefer to reproduce bugs or test functionality “as an API user would”, by probing the outside of the system.
Here’s how it works:
Create or copy a virtual database each time you test an endpoint
Fixture the system from the outside, making all the API calls a user would make (e.g. signing up, creating a Foo)
Reproduce the bug/behavior you want to test
Theses tests make for excellent regression tests, but if you’re able to get the configuration above to work quickly and in parallel (trust me, you can!!) then they’re also incredible for new feature development.
The Perfect Test
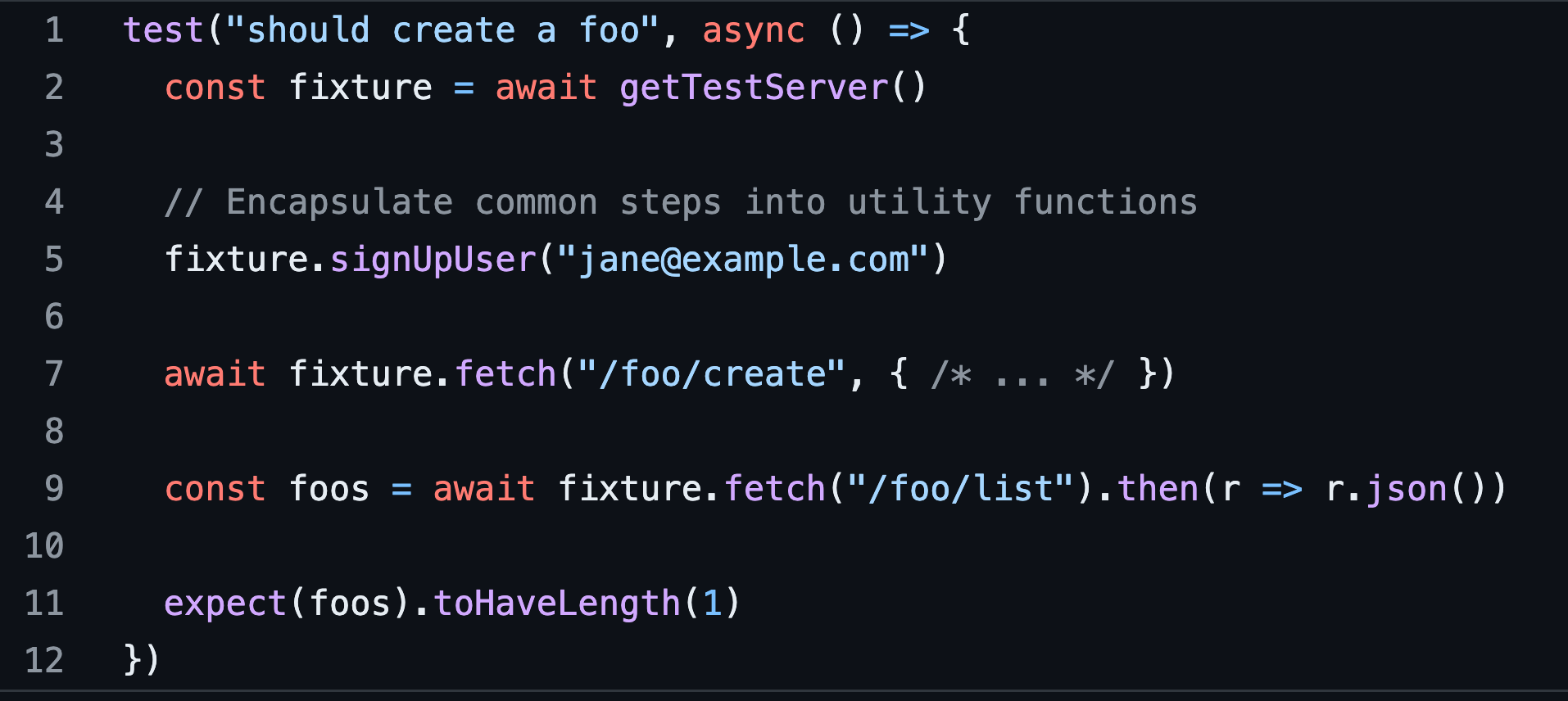
Why is this the perfect test?
We’re using the API exactly like a customer
We’ve encapsulated common steps into fixture functions
Every test has the same import
getTestServerand doesn’t require understanding any internal workings of the server
The thing I love about this pattern is the code your customers/users are using becomes the same code you use to test. You don’t have any “special access” to the insides of your services for tests, which dramatically simplifies how complex the test suite is.
Many people will cheat and put fixture.db as a database client because let’s face it, your database probably has some weird legacy data you have to emulate for some tests. In those cases you might have tweaks or insertions as part of your test. If you’re feeling very lazy with fakes, you can use “internal access hacks” to get around e.g. email verification. A little bit of that is good, a lot of it is very bad!
Setting up your tests
Let’s go through setting up these tests very simply. First let’s get a postgres instance running in the background, passwordless for simplicity:
docker run -d --rm -p 5432:5432 -e POSTGRES_HOST_AUTH_METHOD=trust postgres:16We’ll create all of our virtual databases inside this instance. I like the passwordless version because it requires no setup and is unopinionated, so your test suite can just grab onto postgres at port 5432 without any configuration.
Next let’s write our getTestServer function. This should be the only function that tests need to run!

And that’s basically it! In our fixture we:
Create our temporary virtual database
Create a database client for our application
Inject the database client into our server
A lot of times this is just a middleware that sets
req.db, then whatever middleware normally sets up your database just grabsreq.dbif it’s available
Clean up the test database
Real world example of get-test-server.ts
Talking to External Services (spoiler: use fakes!)
Most people will object to this pattern on the basis that external services are slow. This is absolutely true, which is why you should spin up a fake version of each dependent external service.
This does not mean mocking. You should write a dedicated lightweight module-server (a fake) that can be externally spun up and actually contains business logic. It should live independently of your codebase and only use in-memory data (i.e. it should be really fast). It’s critical that your fake encapsulates your knowledge of the external service. If there’s a bug or quirk of the external service, encode that knowledge into your fake. We’ve built fakes for many external services at this point, and even created a typescript framework for quickly building API server-modules called winterspec. Here’s an example of how you would fixture a test with a fake:

Most SDKs (including the stripe SDK) support replacing the their base API url because they use it for their own testing!
Here’s a conversation I’ve had a million times, but time and time again Engineer 1 comes around that fakes are an incredible pattern for external services. Every company should use these, even if they don’t adopt this database pattern.
Engineer 1: You’re not testing against the real thing! It won’t be as robust!!!
Engineer 2: Actually it’s better than the real thing, because we can simulate scenarios that aren’t easily replicable with the real API, such as downtime or weird errors we see in our production logs!
Engineer 1: That may be so, but the lift of building a fake is a lot! How can we justify the cost?
Engineer 2: The upfront cost of building fakes is high, but the long term benefit is extremely high. We’ll be able to re-use these fakes whenever we integrate against the external service again, and we can easily create E2E tests and have a fast test suite!
Good APIs are generally simple & understandable by design, so they’re generally easy to emulate if you’re not concerned about optimization and scaling.
Fakes: The Upfront Costs
To implement this kind of outside-in testing, you’ll almost always need to implement the following fakes for whatever services you’re using, which will require a deeper understanding of each service than you probably wanted to get- but it’s worth it!
Email Service - however you’re sending emails, e.g. sendgrid
Easiest- you might have already done this one
Auth Service - Auth0, Clerk etc.
These are both the most difficult and highest ROI fakes- someone should really open-source fakes for these!
Payments - Stripe etc.
Also one of the most painful because there’s a lot of logic around computing money- but it’s worth it. Don’t trust Stripe’s test mode, it’s still too slow and difficult to fixture for parallel tests!
Redis, AWS Services, SQS etc.
A lot of people shy away from implementing these because they return binary or XML from endpoints. If you’re pressed on time, implement a fake for the client, not the web service. This means instead of writing a redis service, you would just implement
client.get(“mykey”)andclient.put(“mykey”, “val”). You can then inject your new client in your server middleware.
I’ll write more on fakes in the future- they’re not really the main point of this article!
Making it fast to create new databases
I’ve scaled/seen this pattern scaled to many thousands of tests that can run in under 3 minutes. Here are tips to make it faster:
Instead of migrating each time, migrate a “template database” at the beginning of your test run, then use
CREATE DATABASE testdb TEMPLATE template0;There is a really cool module called ava-postgres we built at Seam that automatically handles starting postgres and doing templating automagically with one
getTestDatabasecall. I still can’t believe Max was able to pull this off!
I’ve never found port-binding to be too slow, but it can be problematic with a lot of tests if you run out of ports. I think you should always bind your main API but you can sometimes get away with exporting a
fetchfunction from your external service fake, then replacing the fetch/request client inside of your SDK clients. No port bind!If you’ve implemented outside-in testing without cheating, you can use load-balancing techniques to run your tests on lambdas or firecracker VMs. This is how you get a test suite with 10,000+ tests to run in under a minute on CI. The basic technique for this:
Deploy a preview of the new version of your server such that a request can be configured to use a different database, e.g. using a header
TestDatabaseNameHave
getTestServerreturn theserverUrlto the external server, and insert a uniqueTestDatabaseNamefor each test server returnedThis technique works particularly well for people who use postgres for everything including job queues and keystores
Conclusion Paragraphs are dumb!
Hope you enjoyed learning about this pattern. I wrote this to link people to because I’ve probably implemented this pattern across 100+ repos and every time people onboard they’re scratching their head wondering why our tests are so uniquely simple.
If you’re interested in fakes or have written similar patterns, I’d love to chat, DM me on twitter!